학교에서 들은 프로그래밍 언어론 강의 내용을 복습하면서 작성한 글입니다.
April 8, 2024 6:41 PM
source code 분석
- lexical analysis
- lexical analyzer : 소스분석(들어온 것이 무엇인지 알 수 있어야함)
- syntax analysis - 문법
- syntax analyzer(parser): 문법에 맞는지 분석 (BNF 로 표시)
- BNF 사용의 장점 → 간결한 구문 설명, parser 만들수 있음, 유지보수 간단
- 컴파일러
- 소스코드-lexical analyzer-syntax analyzer-중간코드
Lexical(Low Level), Syntax(High Level) Analysis 분리 이유
→ Simplicity: 합치면 매우 복잡
→ Efficiency
→ Portability: 여러 lexical analyzer에서 parser 사용가능
Lexical Analysis
lexical analyzer
- 패턴 매칭- regular expression에 따라서
- parser 전체의 low-level로서 제일 먼저 동작: frontend
- 하나의 큰 함수처럼 동작
과정: 들어온 언어의 lexeme 파악 → 이미 저장되어있는 것과 맞는지 확인 → lexical token 만들어서 → parser에게 준다
예) sum : 식별자로 파악 → 다양하게 쓰일 수 있지만 우선은 IDENT 로 파악
reserved word(키워드): 맘대로 identifier로 쓰면 안되지만, lexical analyzer가 보기엔 구분X → keyword만 따로 저장해넣자! → identifier 들어왔을 때 keyword냐 아니냐 결정
Lexical analyzer 만드는 3 방법
- token의 formal expression 작성 예) regular expression
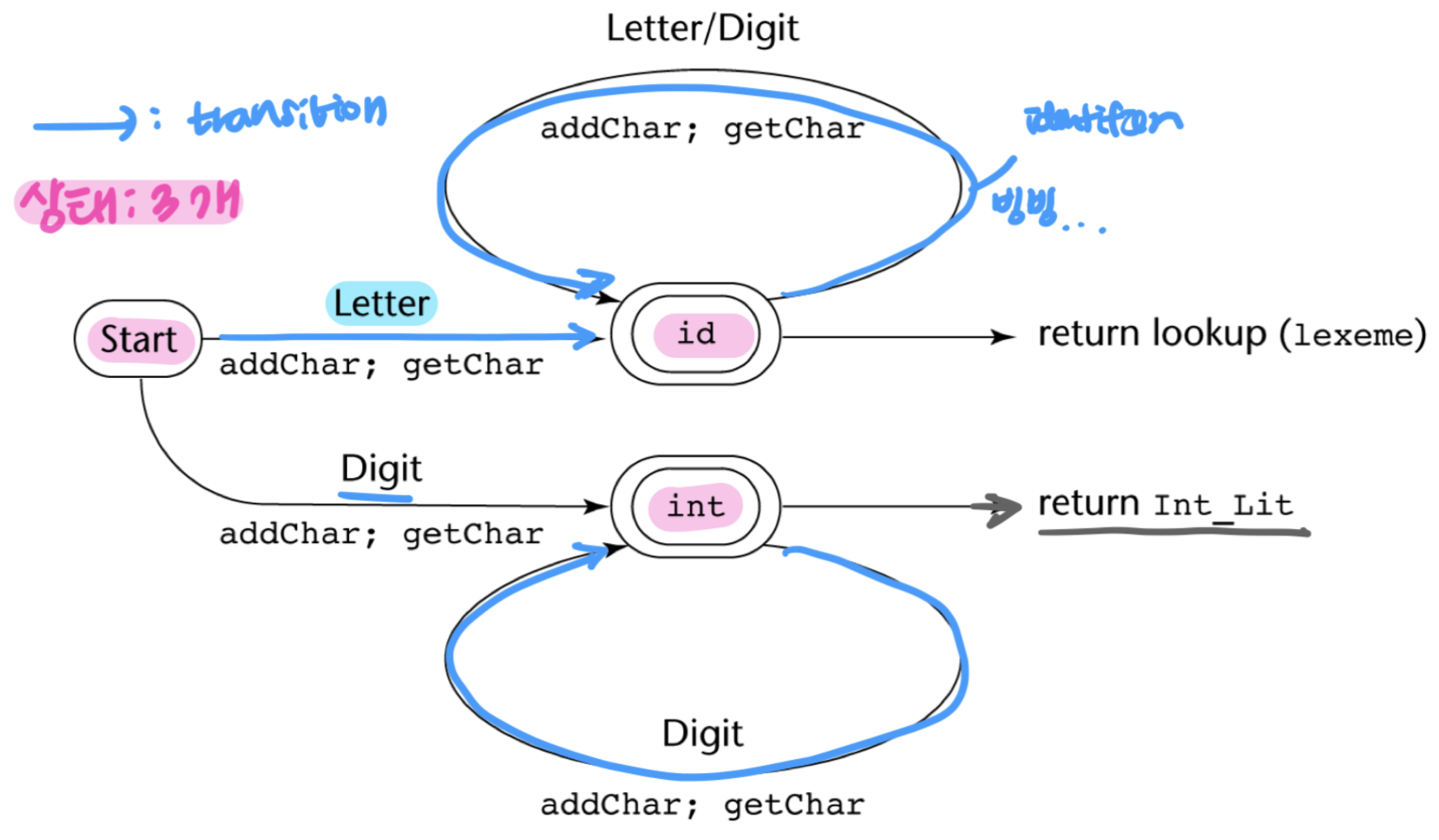
- state diagram(상태도) 만들기 → 들어온게 lexical token인지 아닌지 파악
- 상태도 만들고, 손으로 구현 작성
State Diagram
구성요소
- 상태(의 집합)
- transition(전의): 상태 → 다른 상태로
- 상태도 간단히 만들기 위해, transition combine
- → 글자 하나하나로 분류해서 한 class로 넣어버리자: <>
- reserved words: 맘대로 쓰면 안되지만, lexical analyzer가 보기엔 구분 x → keyword만 따로 저장해놓자!
- identifier 들어왔을 때, keyword냐 아니냐 결정
The Parsing Problem
- parser의 목표: syntax error 찾기, parse tree 만들기(실패 시, 문법 안맞는 부분이 있다는 뜻)
- Parser
- top-down: root에서 시작, leftmost derivation
- bottom-up: leaf에서 시작, reverse of rightmost derivation(=leftmost)
- 어떠한 모호하지 않은 문법(unambiguous grammar)에 대해서도 작동하는 파서(parsers)는 복잡하고 비효율적. 이러한 파서의 효율성은 입력 길이 n에 대해 O(*n^*3)로 표현됨.
- 컴파일러에서는 모든 모호하지 않은 문법에 대해 작동하는 파서보다는, 모호하지 않은 문법들의 부분 집합(subset)에 대해서만 작동하는 파서를 사용. 이런 파서들은 입력 길이 n에 대해 선형 시간(Linear time)인 O(n)의 효율성.
'CS > 프로그래밍 언어론' 카테고리의 다른 글
| [프로그래밍 언어론] Lex (0) | 2024.04.27 |
|---|---|
| [프로그래밍 언어론] Semantics (0) | 2024.04.27 |
| [프로그래밍 언어론] Attribute Grammars (AGs) (0) | 2024.04.27 |
| [프로그래밍 언어론] BNF/EBNF (1) | 2024.04.26 |
| [프로그래밍 언어론] 개요 (0) | 2024.04.26 |